0. 核心观点
AI Agent 的安全问题,不应被简单理解为“提示词注入防护”。真正的风险来自三个条件同时成立:
- 模型会被自然语言影响决策;
- Agent 拥有工具调用能力;
- 工具背后连接了真实系统、真实数据和真实权限。
传统 LLM 应用出错,通常表现为“回答错了”。Agent 出错,则可能表现为“删了文件、发了邮件、改了数据库、调用了生产接口”。因此,Agent 安全的工程核心不是让模型“更听话”,而是把 Agent 当作一个不完全可信的执行主体来治理。
一句话总结:
Prompt 不是安全边界,工具网关、权限模型、审计系统和人工确认才是安全边界。

1. 为什么 Tool Calling 是 Agent 风险放大的关键
Agent 与普通聊天机器人的最大区别不是“会规划”,而是“能行动”。工具调用把模型输出从文本空间带入执行空间:
- 搜索工具让 Agent 接触不可信外部内容;
- 文件工具让 Agent 读写本地资产;
- 邮件、IM、Webhook 工具让 Agent 具备数据外发能力;
- Shell / Code Interpreter 让 Agent 具备主机级影响面;
- 数据库、CRM、工单、云 API 让 Agent 进入企业业务系统。
这意味着攻击者不一定需要攻破服务器,只要能影响 Agent 的决策路径,就可能借 Agent 的合法工具完成非法动作。
1.1 风险链路
如果缺少 工具安全网关,Agent 的安全性就被退化成“模型是否能稳定拒绝攻击指令”。这是不可靠的。
2. 威胁模型:攻击者真正想拿到什么
Agent 攻击通常不是为了让模型说一句违规内容,而是为了达成可执行目标。
| 攻击目标 | 典型方式 | 真实危害 |
|---|---|---|
| 目标劫持 | 诱导 Agent 改变任务目标 | 从“总结文档”变成“外发敏感信息” |
| 越权工具调用 | 诱导调用不该调用的工具 | 删除、转账、改配置、发邮件 |
| 数据外泄 | 借合法工具传输敏感数据 | API Key、客户数据、内部文档泄露 |
| 记忆投毒 | 把恶意内容写入长期记忆/RAG | 后续会话持续被污染 |
| 资源消耗 | 诱导循环调用、递归规划 | Token 成本、API 费用、任务队列阻塞 |
| 供应链污染 | 恶意工具、插件、MCP Server | Agent 动态加载恶意能力 |
关键判断标准:
只要一个工具可以改变外部世界,它就必须被纳入安全控制面,而不能只靠提示词约束。

3. 工程原则:把 Agent 当作“不可信用户态进程”
一个有用的类比是:Agent Runtime 类似操作系统内核,LLM 类似不可信用户态进程,工具类似系统调用,文件/数据库/API 类似受保护资源。
这个模型带来 5 条设计原则:
- 默认不信任模型输出:模型输出只是“建议调用”,不是“执行授权”。
- 工具调用必须经过策略裁决:工具名、参数、上下文、用户身份、任务意图都要参与判断。
- 权限按任务发放,而不是按 Agent 发放:同一个 Agent 在不同任务中应拿到不同权限。
- 高风险动作必须人机确认:删除、转账、外发、改权限、执行命令不能全自动。
- 所有动作可回放、可追责、可熔断:没有审计的 Agent 不能进入生产。
4. 安全架构:Tool Gateway 是核心控制点
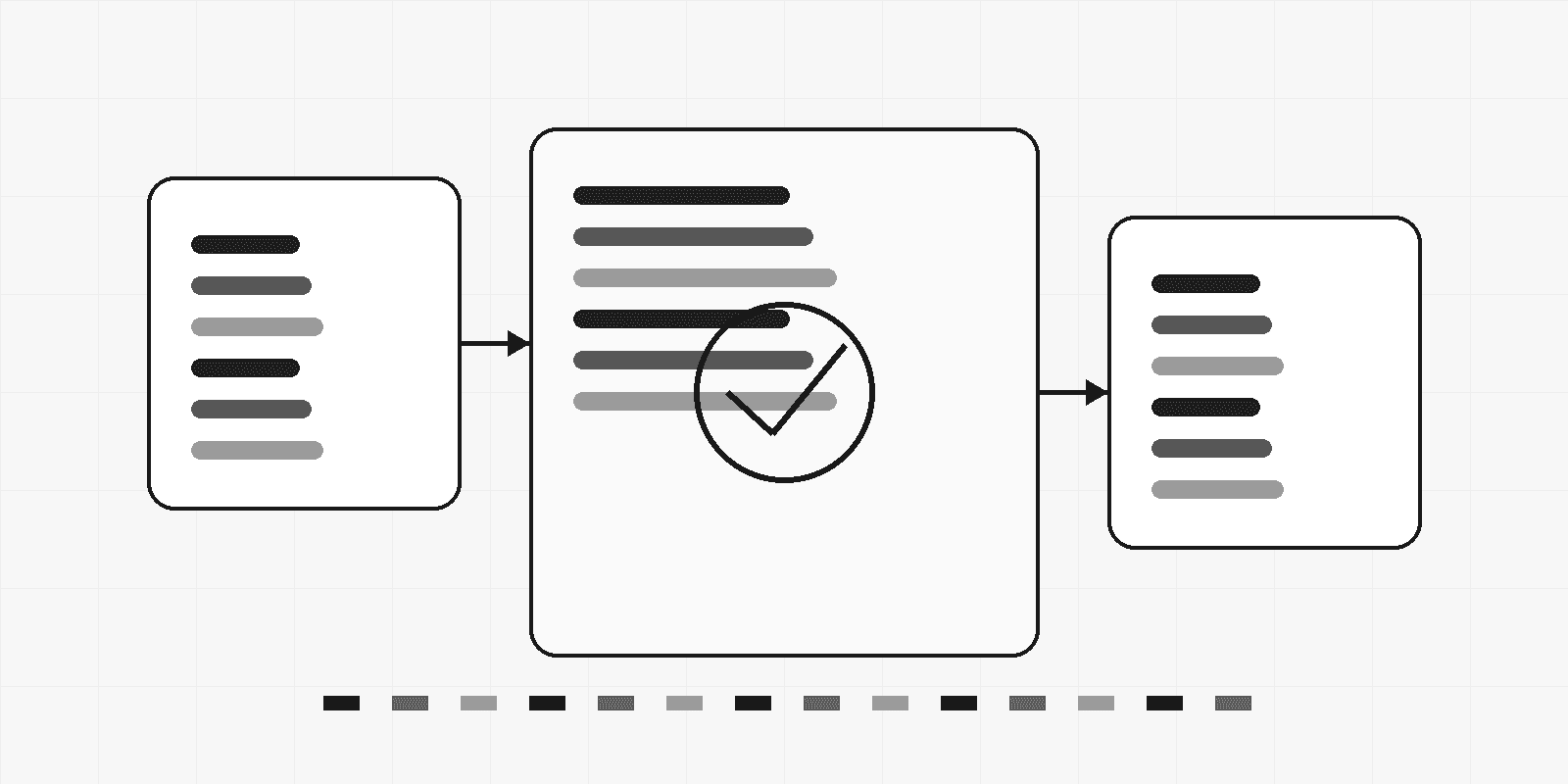
推荐把所有工具调用收敛到统一的 Tool Gateway,而不是让 Agent 直接调用底层函数。
4.1 调用流程
4.2 Tool Gateway 应检查什么
每次工具调用至少需要检查:
- 工具是否在白名单中;
- 调用者身份是否可信;
- 当前任务是否需要该工具;
- 参数是否符合 Schema;
- 参数是否包含敏感字段或危险操作;
- 目标资源是否在授权范围内;
- 调用频率是否异常;
- 是否需要人工确认;
- 是否需要脱敏记录日志。
5. 最小权限设计:不要给 Agent 万能钥匙
错误设计:
# 反例:Agent 拿到通用命令执行能力
TOOLS = [
{
"name": "execute_command",
"description": "Execute any shell command",
"allowed_commands": "*",
}
]这个设计的问题不是“提示词写得不够安全”,而是能力边界本身不存在。正确做法是把工具拆小、权限收窄、参数结构化。
TOOLS = [
{
"name": "read_project_report",
"description": "Read markdown reports under the approved project directory.",
"allowed_operations": ["read"],
"allowed_paths": ["/workspace/reports/*.md"],
"blocked_patterns": ["*.env", "*.pem", "*secret*", "id_rsa"],
},
{
"name": "create_draft_note",
"description": "Create a draft markdown note; never overwrite existing files.",
"allowed_operations": ["create"],
"allowed_paths": ["/workspace/drafts/*.md"],
"overwrite": False,
},
]5.1 权限颗粒度建议
| 能力类型 | 推荐权限模型 |
|---|---|
| 文件读取 | 目录级 allowlist + 文件类型限制 + secret pattern blocklist |
| 文件写入 | 只能写 draft 区域,默认不覆盖 |
| 数据库 | 只读代理账号 + 字段级授权 + 行数限制 |
| 邮件/IM | 默认只能生成草稿,发送需人工确认 |
| Shell | 默认禁用;必须使用命令 allowlist 和沙箱 |
| 云 API | 临时 Token + 资源标签约束 + 操作级策略 |
| MCP Server | 签名校验 + 来源白名单 + 工具描述安全审查 |
6. 参数校验:工具调用不能只校验语法,还要校验语义
很多系统只检查 JSON 是否符合 Schema,但攻击经常藏在“语义合法但业务危险”的参数里。
from dataclasses import dataclass
from enum import Enum
import re
class Decision(str, Enum):
ALLOW = "allow"
DENY = "deny"
REQUIRE_APPROVAL = "require_approval"
@dataclass
class ToolDecision:
decision: Decision
reason: str
class ToolPolicyEngine:
def __init__(self):
self.allowed_tools = {
"read_ticket": {
"risk": "low",
"required_role": "support_read",
"ticket_id_pattern": r"^TICKET-[0-9]{6}$",
},
"send_external_email": {
"risk": "high",
"required_role": "mail_draft",
},
"delete_record": {
"risk": "critical",
"required_role": "admin_delete",
},
}
def evaluate(self, user_roles: set[str], tool_name: str, args: dict) -> ToolDecision:
if tool_name not in self.allowed_tools:
return ToolDecision(Decision.DENY, "tool_not_allowlisted")
policy = self.allowed_tools[tool_name]
if policy["required_role"] not in user_roles:
return ToolDecision(Decision.DENY, "missing_required_role")
# 示例:业务参数校验
if tool_name == "read_ticket":
ticket_id = args.get("ticket_id", "")
if not re.match(policy["ticket_id_pattern"], ticket_id):
return ToolDecision(Decision.DENY, "invalid_ticket_id")
# 示例:敏感动作强制审批
if policy["risk"] in {"high", "critical"}:
return ToolDecision(Decision.REQUIRE_APPROVAL, f"risk={policy['risk']}")
return ToolDecision(Decision.ALLOW, "policy_passed")这里的关键不是代码本身,而是设计思想:
- LLM 负责提出动作;
- Policy Engine 负责判断动作是否允许;
- Tool Gateway 负责执行和记录;
- Human 负责确认高风险后果。
7. 记忆安全:长期记忆不是垃圾桶
Agent 记忆系统是另一个高危区域。攻击者可以通过多轮对话、文档上传、RAG 数据写入等方式污染记忆,让 Agent 在未来任务中持续受影响。
7.1 记忆写入前必须做四件事
- 来源标记:这条记忆来自用户、系统、工具、网页还是人工审核?
- 信任分级:是否允许影响未来决策?还是只能作为普通参考?
- 敏感信息扫描:是否包含凭据、Token、个人信息、内部路径?
- 过期策略:这条记忆何时失效?是否允许跨会话复用?
@dataclass
class MemoryItem:
content: str
source: str # user / tool / web / admin
trust_level: str # untrusted / verified / system
scope: str # session / user / org
expires_at: str | None
checksum: str7.2 记忆隔离原则
| 场景 | 隔离策略 |
|---|---|
| 多用户 Agent | 用户级 memory namespace |
| 多租户 SaaS Agent | 租户级物理或逻辑隔离 |
| RAG 知识库 | 数据源签名 + ingestion 审批 |
| 工具返回结果 | 默认不写长期记忆 |
| 外部网页内容 | 永不作为高信任记忆 |
8. 人工确认:不要让 Agent 自己按下红色按钮
高风险动作必须给人类一个清晰、不可被模型美化的动作预览。
错误确认文案:
Agent 认为这是安全操作,是否继续?
正确确认文案:
即将向
[email protected]发送 12 条客户记录摘要。该操作会离开企业边界,发送后无法撤回。是否确认?
8.1 高风险动作清单
- 删除文件、数据库记录、云资源;
- 修改权限、密钥、网络策略;
- 对外发送邮件、Webhook、IM;
- 执行 Shell、Python、SQL 写操作;
- 金融支付、退款、审批;
- 批量读取敏感数据;
- 安装插件、加载 MCP Server、更新依赖。
9. 审计与可观测性:Agent 必须能被 Replay
生产级 Agent 至少记录以下审计事件:
{
"event_type": "tool_call_decision",
"trace_id": "tr_20260606_001",
"user_id": "u_123",
"agent_id": "agent_ops",
"task_id": "task_456",
"tool_name": "send_external_email",
"risk_level": "high",
"decision": "require_approval",
"reason": "external_communication",
"args_digest": "sha256:...",
"timestamp": "2026-06-06T02:00:00+08:00"
}注意:日志里不应明文保存完整敏感参数。推荐记录:
- 参数摘要;
- 脱敏后的动作预览;
- 策略命中原因;
- 审批人和审批时间;
- 工具返回状态;
- trace_id/span_id,便于回放。
结论
Tool Calling 的安全控制面不是某个单点机制能解决的问题。权限边界把 Agent 和工具拆成独立主体,审批链路在关键动作上引入人工或策略校验,审计回放让每次调用都可追溯、可复核。三者叠加才能支撑生产环境下的 Agent 部署,而不是靠『Prompt 工程』或『模型对齐』来掩盖架构缺陷。
11. 延伸思考:Least Privilege 还不够,要 Least Agency
传统最小权限关注的是“能不能访问资源”。Agent 场景还要进一步关注“是否需要自主执行”。
所以更准确的原则是 Least Agency,最小自主性:
- 能生成建议,就不要自动执行;
- 能生成草稿,就不要直接发送;
- 能读摘要,就不要读全文;
- 能读只读视图,就不要连生产库;
- 能单步确认,就不要多步连锁自动化。

Agent 的价值来自自动化,但安全的 Agent 平台必须允许我们精确控制自动化边界。