0. 核心观点
Agent 记忆不是“把对话塞进向量库”。在生产环境里,长期记忆会参与后续决策,因此它更接近一套可查询的组织知识资产:需要来源、权限、过期策略、召回评估和删除能力。把长期记忆当缓存处理,短期看能提升个性化,长期看会制造污染、越权和不可追溯的自动化行为。
本文的判断是:Agent 记忆系统的第一优先级不是“记得更多”,而是“知道什么可以被记住、何时可以被召回、谁能证明它仍然有效”。
1. 背景与问题定义
现代 Agent 通常同时使用三类状态:会话上下文、任务工作区和长期记忆。会话上下文负责当前推理,工作区保存任务中间产物,长期记忆则跨任务保留事实、偏好、决策和经验。问题在于,长期记忆一旦被无约束写入,就会把一次性的噪声变成可重复召回的“事实”。
典型事故并不复杂:网页中的不可信描述被摘要为用户偏好;临时排障命令被记成默认操作规程;过期的 API endpoint 被长期保留;某个项目的敏感上下文在另一个项目中被召回。模型本身无法稳定区分“被看到的信息”和“被授权长期使用的信息”,这必须由记忆控制面完成。
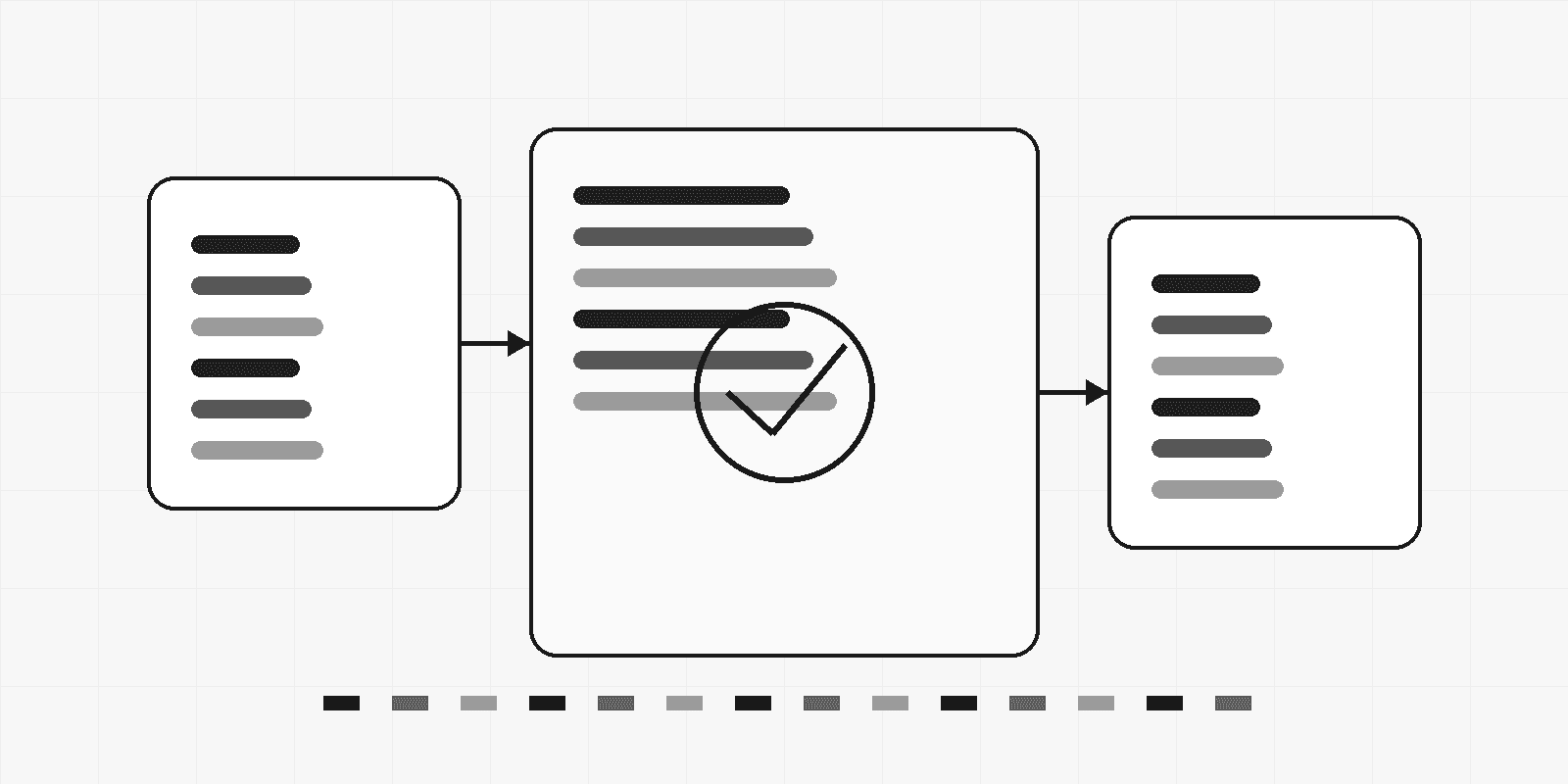
2. 记忆系统的四层设计
| 层级 | 职责 | 工程关注点 |
|---|---|---|
| 写入入口 | 判断哪些内容有资格成为记忆 | 来源标签、敏感度、用户授权、项目边界 |
| 存储模型 | 表达事实、事件、偏好和决策 | schema、版本、过期时间、实体关系 |
| 召回策略 | 决定何时把记忆放回上下文 | relevance、权限过滤、时间衰减、冲突检测 |
| 审计与删除 | 证明记忆从何而来、为何被用 | write log、recall log、delete tombstone |
如果没有写入入口,记忆库会变成噪声仓库;如果没有召回策略,越权风险会被包装成“个性化”;如果没有审计删除,错误记忆会长期影响 Agent 行为却无法定位责任链。
3. 工程化设计
生产级 Agent 记忆至少应实现三类数据契约。
第一是写入契约:每条记忆必须包含 subject、predicate、object、source、scope、ttl、confidence、sensitivity 和 created_at。自然语言摘要可以作为展示字段,但不能替代结构化字段。第二是召回契约:召回请求必须携带 task_id、actor、project、allowed_scopes 和 purpose。第三是证据契约:Agent 输出中使用了长期记忆时,应能回放“哪条记忆被召回、为什么通过过滤、是否被模型实际引用”。
memory = {
"subject": "project:payments-agent",
"predicate": "requires_review_for",
"object": "production-shell-command",
"scope": "project:payments-agent",
"source": {"kind": "decision", "id": "adr-014"},
"ttl_days": 180,
"confidence": 0.92,
"sensitivity": "internal",
}
query = {
"actor": "agent:release-copilot",
"task_id": "deploy-2026-06-08",
"allowed_scopes": ["project:payments-agent"],
"purpose": "deployment-risk-check",
}| 风险场景 | 触发条件 | 控制项 | 可验证证据 |
|---|---|---|---|
| 噪声沉淀为长期事实 | 网页/一次性排障输出被自动摘要 | 写入队列默认待审,要求 source/scope/ttl | rejected_write 日志、写入审批记录 |
| 跨项目越权召回 | query 未携带 project/scope | recall 前强制 scope filter | recall_log 中的 allowed_scopes 与命中文档 |
| 过期事实继续影响决策 | TTL 到期但 embedding 仍可命中 | 召回时检查 expires_at,不只删向量 | expired_hit_rate、tombstone 测试 |
| 删除不完整 | 原文删了但摘要/实体边残留 | 删除 tombstone 级联原文、摘要、实体边、缓存 | delete verification suite |
4. 最小可复现实验:验证“越权记忆不会被召回”
可以先不用真实向量库,用一组固定样本验证控制面是否生效。下面的脚本故意放入两个项目的记忆,并让 payments-agent 查询“生产发布要注意什么”。正确结果只能返回 payments 范围内的记录。
memories = [
{"id": "m1", "scope": "project:payments", "text": "生产 shell 命令必须走变更审批", "ttl_ok": True},
{"id": "m2", "scope": "project:hr", "text": "HR 数据导出需要 DPO 许可", "ttl_ok": True},
{"id": "m3", "scope": "project:payments", "text": "旧版发布脚本可以直连主库", "ttl_ok": False},
]
query = {"allowed_scopes": ["project:payments"], "purpose": "release-risk-check"}
result = [m for m in memories if m["scope"] in query["allowed_scopes"] and m["ttl_ok"]]
assert [m["id"] for m in result] == ["m1"]
print(result)这类测试比“召回率看起来不错”更接近生产风险:m2 代表跨域越权,m3 代表过期事实残留。真正上线前,应把这类样本固化成 CI 门禁;任何一条越权召回都不应该被平均分掩盖。
5. 评估:不要只测召回率
记忆系统常见的误区是只看“是否召回相关事实”。这只覆盖了有用性,没有覆盖安全性。更合理的评估集应同时包含:该召回的事实、不能召回的跨项目事实、过期事实、互相冲突的事实、低置信度事实,以及被删除后不应再出现的事实。
发布门禁的底线很简单:权限违规率和删除后残留率不能用平均分掩盖,任何可复现的严重违规都应阻断发布。
6. 风险与安全边界
长期记忆会扩大 Agent 的影响半径。防线不应放在提示词里,而应放在写入、召回、执行三个位置。写入阶段拒绝不可信来源自动沉淀;召回阶段按任务、主体和数据域过滤;执行阶段要求工具网关记录“本次动作是否依赖长期记忆”。
敏感场景还需要“记忆沙箱”:同一用户在不同客户、项目或安全域中的记忆默认隔离。跨域共享必须显式声明,并记录共享原因。删除也不能只是从向量索引移除一条 embedding,还要清理原文、摘要、实体边、缓存和评估样本。
结论
Agent 记忆的治理边界不是技术问题,而是组织问题。谁来决定哪些信息可以长期保留、哪些必须过期、谁有权删除、删除后如何验证——这些需要产品、安全、合规和工程共同定义策略,再由技术实现强制执行。