在 SOC 场景中引入大模型,最容易被误解为“让 AI 自动处置告警”。这是一种危险的简化。真实的安全运营并不是把一条告警映射为一个动作,而是在不完整、噪声高、责任边界明确的环境中建立可解释判断:这条告警意味着什么、它依赖哪些证据、哪些上下文会改变严重性、现有结论的置信度是多少、后续动作是否需要人工批准,以及最终结论能否被审计和复盘。
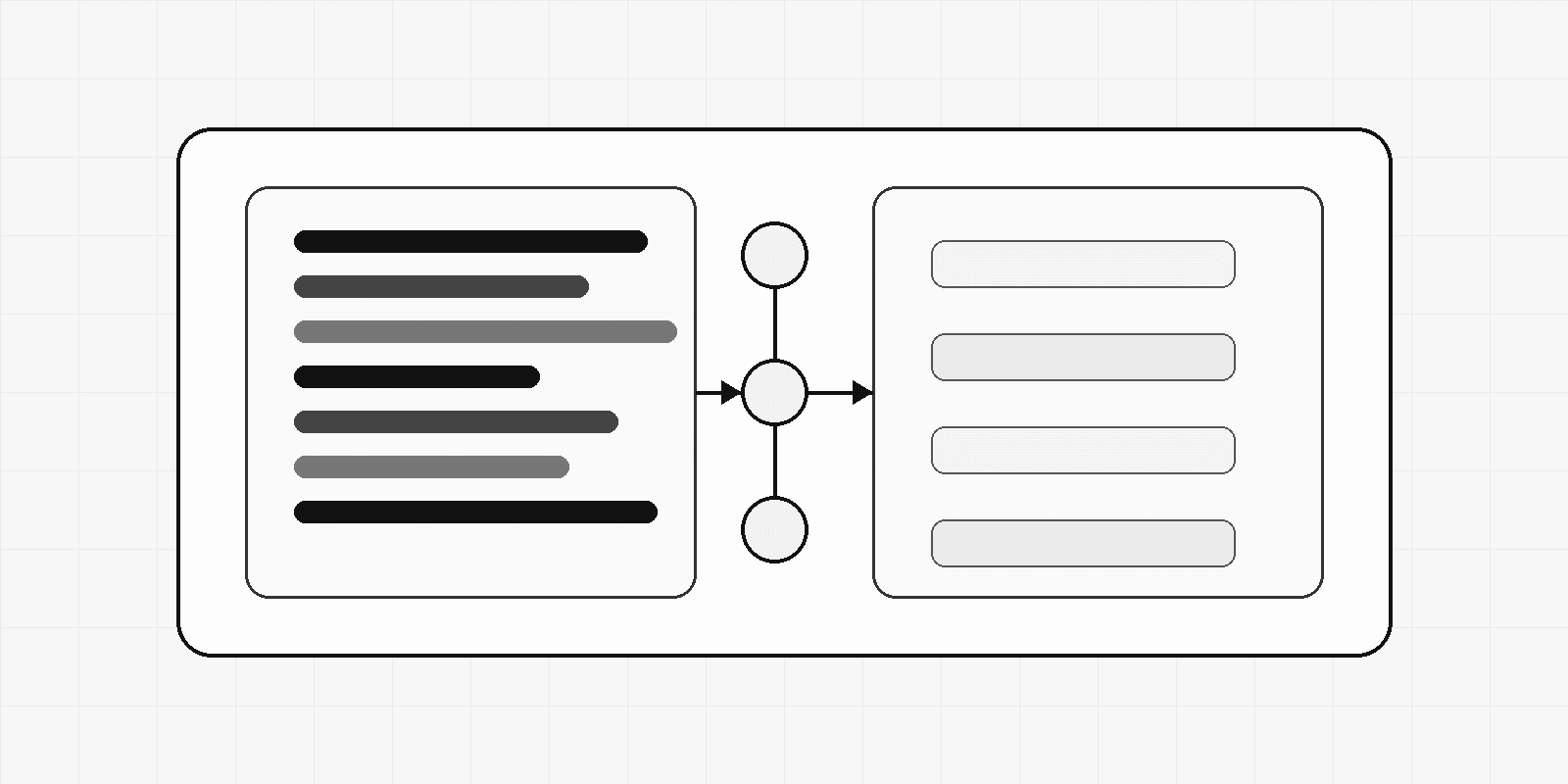
因此,AI SOC Copilot 的核心价值不应首先放在自动隔离主机、封禁账号或删除文件上,而应放在告警研判链路的工程化增强:解释告警、收集证据、关联上下文、形成假设、给出置信度、暴露不确定性,并生成可追溯的证据包。只有当组织已经定义了明确的策略闸门、动作白名单和回滚机制时,才应把部分低风险动作交给自动化执行。
1. 从“自动响应”转向“可审计研判”
SOC 告警处理的难点通常不在于动作本身,而在于动作之前的判断。一个“可疑登录”告警可能是员工出差、VPN 出口变化、凭据泄露、云端服务账号误用,也可能只是身份系统同步延迟造成的噪声。一个 EDR 的“PowerShell 可疑行为”告警可能指向攻击链,也可能来自运维脚本、软件分发工具或安全扫描器。若 Copilot 在缺乏上下文的情况下直接处置,会把误报成本从分析人员转移到业务系统。
较稳妥的架构是把 Copilot 定位为研判助手,而不是最终裁决者。它可以执行高频、重复、低创造性的分析动作,例如字段解析、查询构造、日志聚合、时间线整理、TI 命中解释、资产信息补全和历史案例检索;但对于影响业务可用性、用户权限或数据完整性的动作,需要显式的策略控制与人工确认。
这一区分非常关键。SOC 不是单纯追求速度的流水线,而是带有责任约束的控制系统。Copilot 的输出必须能够回答三个问题:第一,为什么认为这是某类安全事件;第二,证据来自哪里,是否可复核;第三,如果判断错误,系统如何发现、纠正并追责。

上图展示了一个较合理的控制环:告警解释产生初始假设,证据收集验证或否定假设,上下文关联调整严重性,研判结论输出置信度与反证,随后经过策略闸门和人工复核进入审计与学习。这个循环强调的是“判断质量”,而不是“动作速度”。
2. 告警对象:Copilot 必须先理解字段语义
告警研判的输入不是自然语言问题,而是一组结构化和半结构化字段。Copilot 的第一步应是把告警字段转换为可分析对象,识别字段之间的因果和时间关系,而不是直接生成总结。
一个标准化的 SOC 告警对象至少应包含以下类别:
- 告警元数据:alert_id、source、rule_id、rule_name、rule_version、severity、confidence、created_at、updated_at、tenant、workspace。
- 检测逻辑信息:触发规则描述、查询语句或检测签名、阈值、窗口期、MITRE ATT&CK 技术映射、规则最近变更记录。
- 主体与客体:user、host、process、file、ip、domain、url、cloud_resource、service_account、container、namespace。
- 事件时间线:first_seen、last_seen、event_count、相关原始日志时间戳、采集延迟、时区。
- 证据引用:原始日志 ID、SIEM 查询链接、EDR 进程树快照、身份系统登录记录、网络流量摘要、TI 命中来源。
- 环境上下文:资产重要性、业务归属、暴露面、补丁状态、最近变更、用户部门、值班窗口、例外策略。
- 处理状态:owner、case_id、suppression 状态、历史处置、关联工单、人工备注。
字段理解阶段的目标是形成“待验证问题列表”。例如:规则是否针对真实攻击技术;告警主体是否为关键资产;该用户是否有异常地理位置或设备指纹变化;相关 IP 是否只被低可信 TI 标记;进程链是否存在父子关系异常;同一资产在近 24 小时内是否出现横向移动、凭据访问或持久化迹象。
Copilot 在这里应避免过度推断。正确做法是把告警解释成一组假设和待查证点,例如“可能是凭据滥用,但需要验证 MFA 状态、设备合规性和登录后行为”;而不是直接写出“攻击者正在使用被盗账号”。
3. 证据链:把查询、结果和推理分离保存
在传统 SOC 中,分析人员常常在多个控制台之间切换:SIEM 查日志,EDR 看进程树,TI 平台查 IP 和域名,CMDB 查资产归属,身份系统查登录历史,工单系统查历史例外。Copilot 可以显著降低这种检索成本,但必须保留证据链,而不是只保留模型生成的结论。
证据链应至少包括三层:
- 查询层:使用了哪些查询、参数、时间窗口和数据源。例如 SIEM 查询语句、EDR API 参数、TI 查询对象、CMDB 资产 ID。
- 结果层:返回了哪些原始或摘要结果。例如日志条数、关键字段、进程树、登录记录、TI reputation、资产标签。
- 推理层:模型如何根据结果支持或反驳假设。例如“同一账号在 15 分钟内从两个国家登录,且后续访问了未曾访问的管理控制台,因此凭据风险上升”。
这三层不能混在一段自然语言里。查询层和结果层需要机器可读,便于审计、复跑和差异分析;推理层可以是自然语言,但必须引用证据 ID。工程实现上,可把每个 evidence item 表示为如下结构:
evidence_id: ev-0042
source: siem
query: "SigninLogs | where UserPrincipalName == ..."
time_range: "2026-06-06T14:00:00Z/2026-06-06T16:00:00Z"
result_summary: "3 failed logins followed by 1 successful MFA login from new ASN"
raw_refs:
- "siem://workspace/case/alert-123/event/98765"
supports:
- "hypothesis.credential_abuse"
contradicts: []
quality:
freshness: "high"
completeness: "medium"
source_reliability: "high"这样的结构可以约束 Copilot:它不能凭空补全证据,不能把 TI 的低置信命中当作确定事实,也不能在没有原始引用的情况下把推理包装成结论。
4. 研判链路:从解释到结论的工作流
一个面向生产的 AI SOC Copilot 可以采用如下链路:
这条链路中有几个设计要点。
首先,证据收集计划应由告警类型驱动,而不是固定查询模板。例如身份类告警优先查 IAM、MFA、设备合规性、地理位置、条件访问策略和登录后行为;恶意文件告警优先查 EDR 文件哈希、进程树、父进程、落地路径、签名、横向传播迹象;云资源告警则需要查 IAM policy 变更、CloudTrail/Activity Log、资源标签和最近 IaC 发布记录。
其次,RAG 知识库不应只用于“回答安全知识”,而应提供组织内部上下文。包括检测规则说明、误报案例、资产分级标准、例外审批记录、应急预案、变更窗口、业务系统拓扑、过往 incident postmortem。没有内部知识的 Copilot 只能做通用解释,无法判断“这个域控测试环境是否允许执行该脚本”或“这个服务账号是否本来就会跨区域访问对象存储”。
第三,置信度应是可解释的综合结果,而不是模型自报的主观分数。它应受到证据一致性、数据源可靠性、时间接近性、实体匹配质量、历史误报率和反证强度影响。例如 TI 命中来自单一低质量 feed,只能轻微提高风险;EDR 进程树显示 Office 子进程启动编码 PowerShell,并伴随外联和凭据访问行为,则显著提高置信度;CMDB 显示主机属于安全演练靶场,则需要降低业务处置优先级但不一定降低检测真实性。
5. 多 Agent 不是多聊天机器人,而是职责隔离
许多实现会把“多 Agent”理解为多个模型互相讨论。对 SOC 而言,更有价值的设计是职责隔离和权限隔离。不同 Agent 访问不同工具、承担不同验证任务,并把结果写入统一证据仓库。协调器负责计划与合并,但不能越权执行高风险动作。
在这个模型中,SIEM Connector 只负责查询日志,EDR Connector 只负责读取主机遥测或执行已批准的低风险动作,TI Connector 只返回情报命中和来源质量,CMDB Connector 返回资产关键性和业务归属,IAM Connector 返回身份上下文。Reasoning Agent 可以请求证据,但不能伪造证据;Audit Agent 检查结论中的每个关键断言是否有 evidence_id 支撑;SOAR Policy Gate 决定动作是否允许自动执行。
这种架构的收益是可控性。即使模型发生幻觉,审计层也可以发现“结论引用了不存在的证据”或“高风险动作缺少审批”。即使某个工具返回异常,协调器也能把结论标记为“证据不足”,而不是继续生成看似完整的报告。
6. 输出格式:结论必须包含不确定性和下一步
Copilot 的最终输出不应只是“高危/中危/低危”的自然语言摘要,而应包含可操作但受约束的研判结构。一个较完整的输出包括:
- 一句话结论:当前最可能的解释。
- 严重性重估:原始 severity 与重估 severity,以及变化原因。
- 置信度:高、中、低或数值分段,并解释依据。
- 关键证据:按支持证据、反证、缺失证据列出,并引用 evidence_id。
- 时间线:按时间排序列出关键事件,避免倒因为果。
- 影响范围:涉及账号、主机、资源、网络位置和潜在业务影响。
- 推荐动作:区分立即人工确认、低风险自动动作、需要审批的高风险动作。
- 审计信息:使用的数据源、查询时间窗口、模型版本、规则版本、策略版本。
例如,对于一个可疑登录告警,Copilot 可以输出:“当前更可能是账号风险事件而非单纯误报,置信度中等偏高。支持证据包括新 ASN 登录、MFA push 异常、登录后访问管理控制台;反证是设备已注册且地理位置与近期出差申请部分一致。建议人工联系用户确认,并在确认前临时提高会话风险级别;不建议自动禁用账号,因为该账号关联生产发布流程。”
这个输出比“检测到账号被盗,建议封禁”更有工程价值。它让分析人员看到判断边界,也让后续审计者知道为什么没有立即封禁账号。
7. 自动化边界:低风险动作可以自动,高风险动作必须受控
AI SOC Copilot 可以接入 SOAR,但自动化动作需要分层。可自动执行的通常是低风险、可逆、不会显著影响业务的动作,例如补充查询、创建 case、给资产打临时标签、提高监控级别、请求用户确认、收集 EDR triage package、把恶意哈希加入观察列表。需要审批的动作包括隔离生产主机、禁用关键账号、阻断核心业务 IP、删除文件、修改 IAM policy、回滚云资源配置。
策略闸门至少应考虑以下条件:
- 动作是否在白名单内;
- 目标资产是否为关键业务系统;
- 置信度是否达到阈值;
- 是否存在强反证;
- 是否有最近变更或维护窗口;
- 是否具备回滚路径;
- 是否需要双人审批;
- 是否违反合规或数据保留要求。
从治理角度看,Copilot 的权限应比分析人员更小,而不是更大。它可以加速证据准备,但不应因为“模型判断高危”就绕过组织的变更和应急流程。
8. 评估指标:衡量研判质量而不是只看响应时间
引入 Copilot 后,常见指标是平均研判时间下降多少、每人每天处理多少告警。这些指标有价值,但不足以说明系统可靠。更重要的指标包括:证据引用完整率、结论可复核率、误报压降质量、漏报补救率、人工驳回率、自动动作回滚率、查询失败率、RAG 命中有效率、规则解释准确率、审计日志完整率。
还应关注“校准”问题:Copilot 标记高置信的结论是否真的更可靠;低置信结论是否有效提示了证据缺口;不同数据源缺失时,模型是否会诚实降低置信度。一个可信的 Copilot 不一定总能给出答案,但必须能在证据不足时停止推断。
评估集可以来自历史 case、红队演练、误报样本和已复盘 incident。每个样本应包含标准证据、预期判断、允许的查询范围和不可接受的处置动作。评估时不仅比较最终标签,还要比较证据路径和推理过程。如果模型给出了正确标签但引用了错误证据,这在 SOC 中仍然是不合格的。
9. 落地建议:先做“副驾驶”,再谈自动闭环
实际建设可以分三阶段推进。
第一阶段是只读 Copilot。它接入 SIEM、EDR、TI、CMDB、IAM 和知识库,但只生成解释、证据包和建议,不执行处置动作。这个阶段重点建立告警对象模型、证据结构、RAG 内容治理和审计日志。
第二阶段是受控辅助处置。Copilot 可以触发低风险 SOAR playbook,例如拉取 triage package、创建工单、通知值班人员、添加观察标签。所有动作都需要策略记录,关键动作仍由人工批准。
第三阶段才是有限闭环。只有对于高重复、低影响、回滚充分的场景,才允许自动执行。例如对已确认测试环境中的低风险误报进行抑制建议,或对已知恶意 IOC 触发临时监控增强。即便进入闭环,也应定期抽样审计,并保留人工随时接管的机制。
结语
AI SOC Copilot 的正确方向不是把 SOC 变成无人值守的自动处置系统,而是把告警研判变成更快、更一致、更可审计的工程流程。它应先理解告警字段,再收集证据,随后关联资产、身份、威胁情报和内部知识,最后给出带有置信度、反证和审计引用的结论。
在高风险安全运营中,速度只有在可解释和可控的前提下才有意义。一个成熟的 Copilot 不应急于按下“隔离”按钮,而应把分析人员原本需要二十分钟完成的证据整理压缩到两分钟,并清楚说明:我们知道什么、不知道什么、为什么这样判断、下一步动作的风险在哪里。这样的系统才可能真正提升 SOC 的判断质量,而不是制造更快的错误。